
Taras Lehinevych
PhD student, former intern at IBM Research Zurich
PhD student, former intern at IBM Research Zurich
Vinodh Venkatesan, Taras Lehinevych, Giovanni Cherubini, Andrii Glybovets, and Mark Lantz
IEEE International Congress on Big Data (BigData Congress), 2018
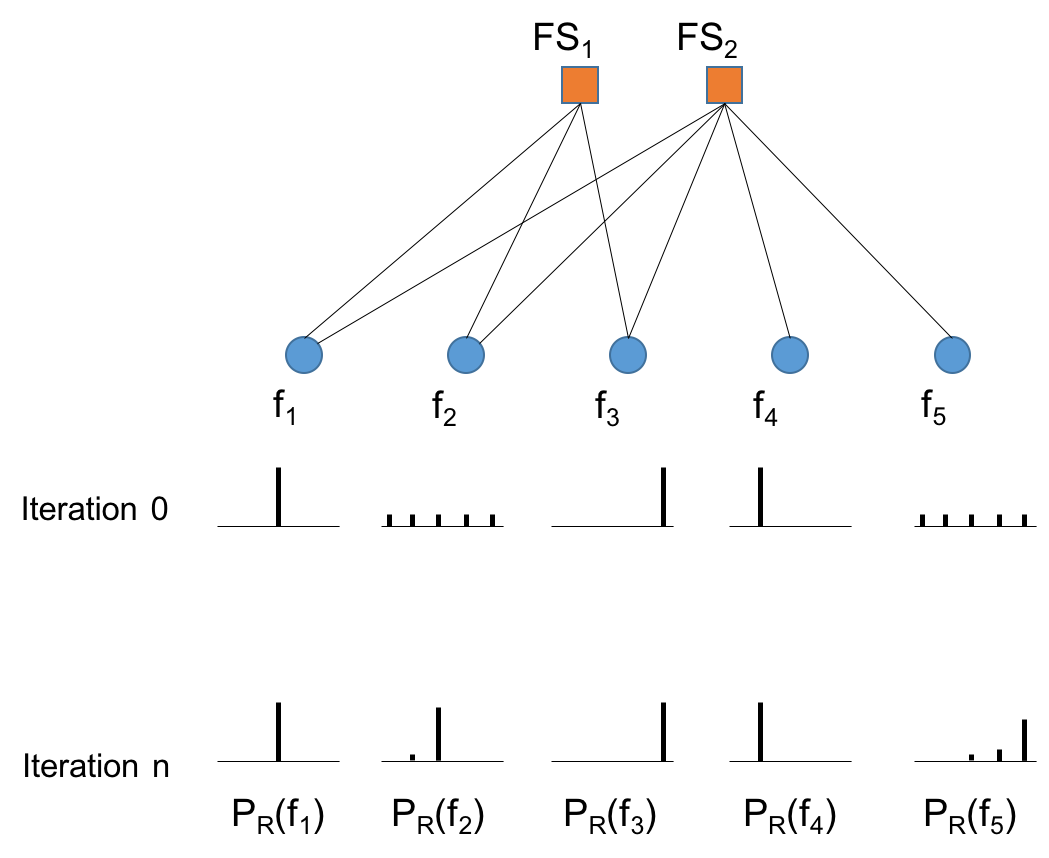
In storage systems, the relevance of files to users can be taken into account to determine storage control policies to reduce cost, while retaining high reliability and performance. The relevance of a file can be estimated by applying supervised learning and using the metadata as features. However, supervised learning requires many training samples to achieve an acceptable estimation accuracy. In this paper, we propose a novel graph-based learning system for the relevance estimation of files using a small training set. First, files are grouped into different file-sets based on the available metadata. Then a parameterized similarity metric among files is introduced for each file-set using the knowledge of the metadata. Finally, message passing over a bipartite graph is applied for relevance estimation. The proposed system is tested on various datasets and compared with logistic regression.
Taras Lehinevych, Nikolaos Kokkinis-Ntrenis, Giorgos Siantikos, A Seza Dogruoz, Theodoros Giannakopoulos, and
Stasinos Konstantopoulos
Tenth International Conference on Signal-Image
Technology and Internet-Based Systems, 2014
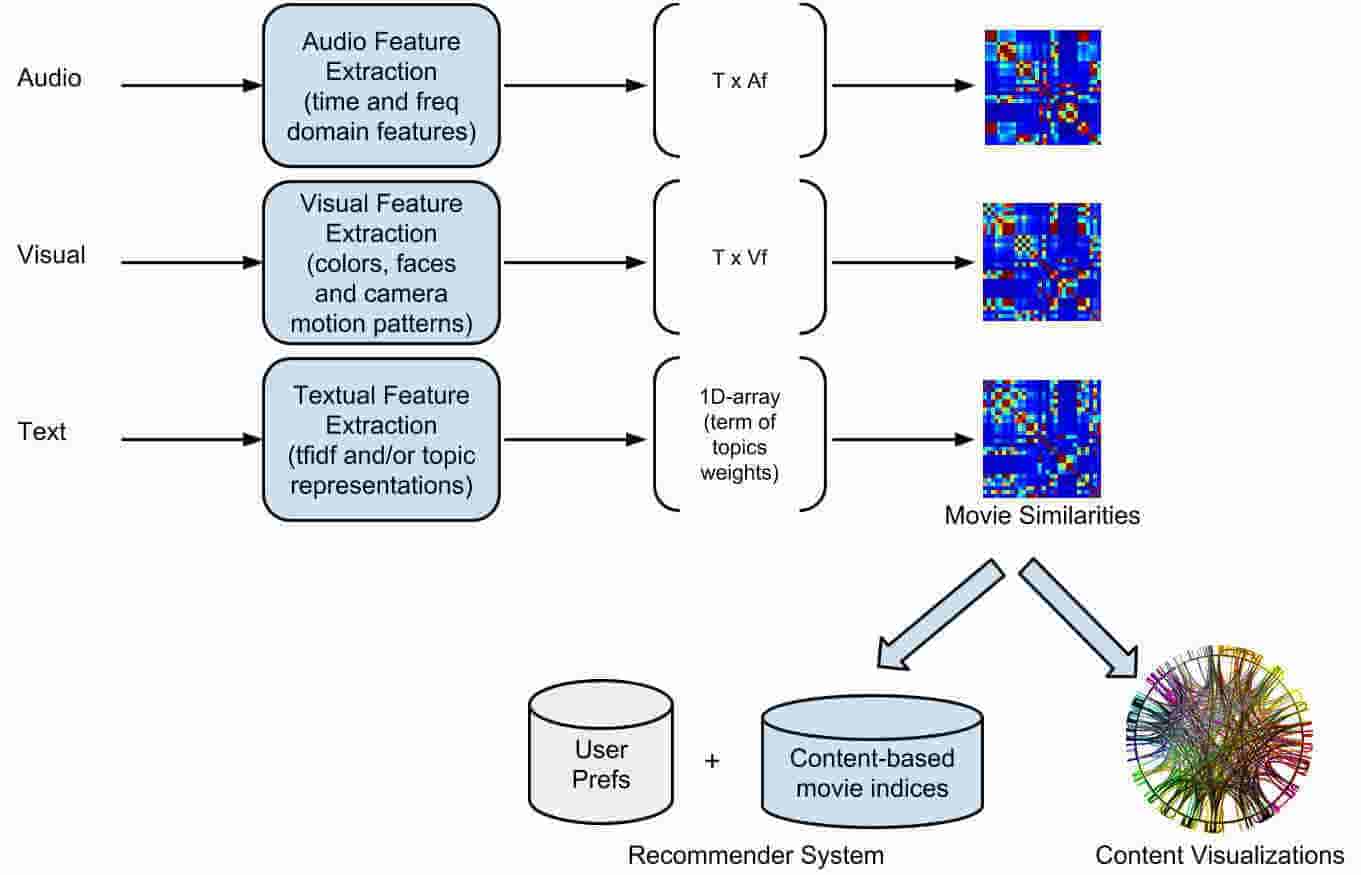
The purpose of the research described in this paper is to examine the existence of correlation between low level audio, visual and textual features and movie content similarity. In order to focus on a well defined and controlled case, we have built a small dataset of movie scenes from three sequel movies. In addition, manual annotations have led to a ground-truth similarity matrix between the adopted scenes. Then, three similarity matrices (one for each medium) have been computed based on Gaussian Mixture Models (audio and visual) and Latent Semantic Indexing (text). We have evaluated the automatically extracted similarities along with two simple fusion approaches and results indicate that the low-level features can lead to an accurate representation of the movie content.
Course: Introduction to Machine Learning
National University of Kyiv Mohyla
Academy
Talk: A Neural Conversational Model
Rails Reactor, Kyiv, Ukraine
Talk: Apache Spark: Scala vs Python
PyCon Ukraine 2016, Lviv, Ukraine
What we do in the Shadows GANs
Rails Reactor, Kyiv, Ukraine
Shadows Generation in the Wild
Data Science fwdays'19, Kyiv, Ukraine